Home>Technology and Computers>Terraform S3 Cross Region Replication From An Unencrypted Bucket To An Encrypted Bucket
Technology and Computers
Terraform S3 Cross Region Replication From An Unencrypted Bucket To An Encrypted Bucket
Published: January 23, 2024
Learn how to set up cross-region replication in Terraform from an unencrypted S3 bucket to an encrypted one. Explore the technology and computer aspects of this process.
(Many of the links in this article redirect to a specific reviewed product. Your purchase of these products through affiliate links helps to generate commission for Noodls.com, at no extra cost. Learn more)
Table of Contents
Introduction
In the world of cloud computing, Amazon Web Services (AWS) has revolutionized the way organizations manage and store their data. One of the key services offered by AWS is Amazon Simple Storage Service (S3), a scalable and secure object storage solution designed to store and retrieve any amount of data from anywhere on the web. S3 provides a highly durable and available storage infrastructure, making it an ideal choice for businesses of all sizes.
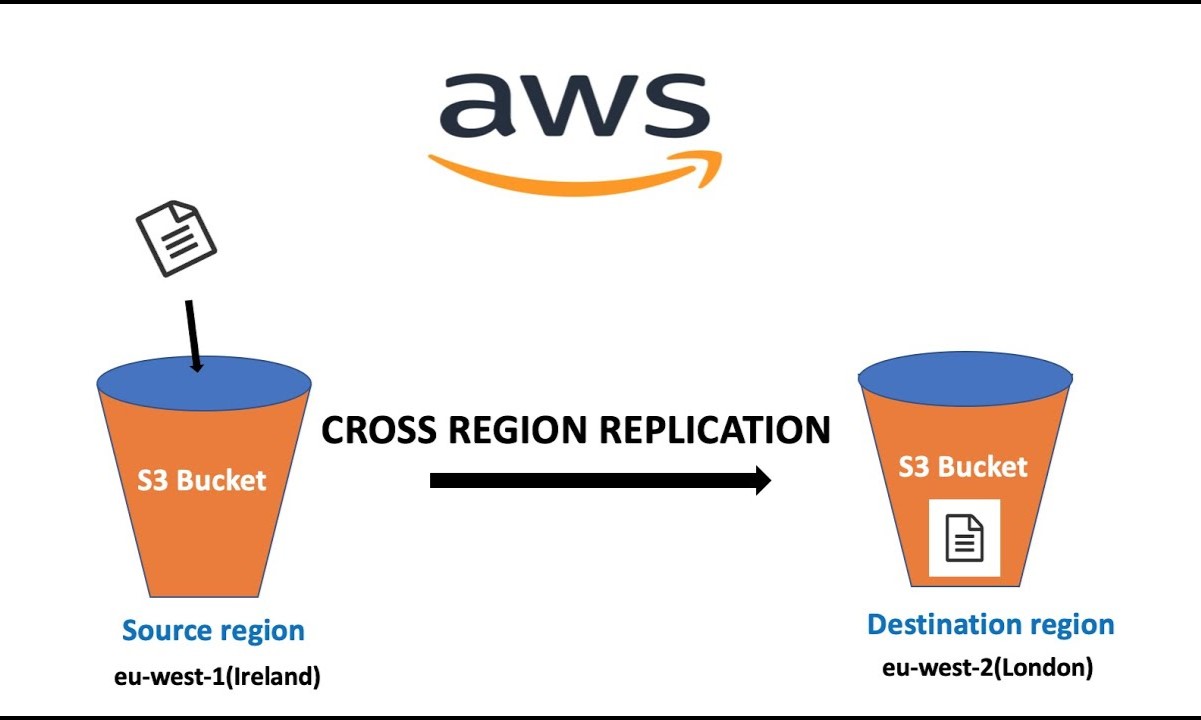
S3 Cross Region Replication is a feature that allows users to automatically replicate data across different AWS regions. This capability is invaluable for ensuring data redundancy, disaster recovery, and compliance with data sovereignty requirements. By leveraging S3 Cross Region Replication, organizations can enhance their data resilience and mitigate the risk of data loss due to region-specific outages or disasters.
In this article, we will delve into the intricacies of setting up S3 Cross Region Replication using Terraform, an infrastructure as code tool that enables users to define and provision AWS infrastructure in a declarative manner. We will explore the process of configuring replication from an unencrypted S3 bucket to an encrypted S3 bucket, highlighting the steps involved and the key considerations for a seamless implementation.
By the end of this article, readers will have a comprehensive understanding of the significance of S3 Cross Region Replication, the role of Terraform in automating the replication setup, and the best practices for monitoring and testing the replication process. Whether you are a seasoned cloud architect or a newcomer to AWS, this article aims to equip you with the knowledge and insights needed to harness the power of S3 Cross Region Replication for robust data management and disaster recovery strategies.
Read more: AWS Reinvent 2020 Day 1 S3 Announcements
Understanding S3 Cross Region Replication
S3 Cross Region Replication is a pivotal feature offered by Amazon Web Services (AWS) that enables automatic and asynchronous replication of data across different AWS regions. This capability plays a crucial role in enhancing data resilience, disaster recovery, and compliance with regulatory requirements. By replicating data across geographically distinct regions, organizations can mitigate the risk of data loss due to region-specific outages, natural disasters, or other unforeseen events.
Key Concepts
Source and Destination Buckets
In the context of S3 Cross Region Replication, the source bucket refers to the S3 bucket from which the data is replicated, while the destination bucket is the target bucket where the replicated data is stored. It is important to note that the source and destination buckets can be located in different AWS regions, allowing for cross-region replication.
Replication Rules
Replication rules define the criteria for which objects in the source bucket are replicated to the destination bucket. These rules can be configured to include or exclude specific objects based on prefixes, tags, or other attributes. Additionally, users have the flexibility to specify whether to replicate the entire bucket or only objects that meet certain criteria.
Cross-Region Asynchronous Replication
S3 Cross Region Replication operates asynchronously, meaning that changes to objects in the source bucket are replicated to the destination bucket with a certain degree of latency. This asynchronous nature allows for efficient replication without impacting the performance of the source bucket.
Benefits and Use Cases
Data Redundancy and Disaster Recovery
By replicating data across different AWS regions, organizations can achieve data redundancy, ensuring that critical data is available even in the event of a regional outage or failure. This redundancy is instrumental in disaster recovery scenarios, enabling swift recovery and continuity of operations.
Compliance and Data Sovereignty
S3 Cross Region Replication facilitates compliance with data sovereignty requirements by allowing organizations to store data in specific geographic regions to adhere to regulatory mandates. This is particularly important for industries with stringent data residency regulations.
Enhanced Performance and Availability
Replicating data to geographically distributed regions can improve data access performance for users located in different parts of the world. Additionally, it enhances the availability of data by reducing the impact of regional disruptions on data accessibility.
In summary, S3 Cross Region Replication is a powerful mechanism for ensuring data resilience, disaster recovery preparedness, and regulatory compliance. Understanding the key concepts and benefits of this feature is essential for leveraging its full potential in architecting robust and resilient data management solutions within the AWS ecosystem.
Setting Up Terraform for S3 Cross Region Replication
Setting up Terraform for S3 Cross Region Replication involves leveraging Terraform’s declarative syntax to define the necessary AWS resources, policies, and configurations for orchestrating the replication process. Terraform simplifies the infrastructure provisioning and management tasks, allowing users to codify the desired state of their AWS environment and automate the deployment of resources.
Terraform Configuration Files
The first step in setting up Terraform for S3 Cross Region Replication is to create the Terraform configuration files. These files, typically named with a .tf extension, contain the infrastructure code that specifies the AWS resources to be provisioned, including the source and destination S3 buckets, replication rules, and any required IAM policies.
AWS Provider Configuration
Terraform requires the configuration of the AWS provider to establish the connection with the AWS environment. This involves specifying the AWS access key, secret key, region, and other relevant settings. By defining the AWS provider configuration in the Terraform files, users can ensure that the replication setup targets the intended AWS region and resources.
S3 Bucket and Replication Configuration
Within the Terraform configuration files, users can define the source and destination S3 buckets for cross-region replication. This includes specifying the bucket names, region-specific settings, and enabling versioning and encryption as per the replication requirements. Additionally, replication rules can be codified to determine which objects are replicated and the replication behavior.
IAM Role and Policies
To facilitate the replication process, Terraform allows for the creation of IAM roles and policies that grant the necessary permissions for S3 Cross Region Replication. These policies define the permissions for accessing the source and destination buckets, initiating replication tasks, and managing the replication configuration.
Read more: How To Make A Bucket In Minecraft
Terraform Apply
Once the Terraform configuration files are defined, users can execute the ‘terraform apply’ command to apply the configuration and provision the specified AWS resources. Terraform will analyze the desired state, detect any variance from the current state, and execute the necessary API calls to create or modify the resources accordingly.
By following these steps and leveraging Terraform’s capabilities, users can seamlessly set up S3 Cross Region Replication, automate the configuration of replication rules, and ensure the consistent provisioning of the required AWS resources. This approach not only streamlines the replication setup process but also promotes infrastructure consistency and repeatability through code-based configuration management.
Configuring Replication from an Unencrypted Bucket to an Encrypted Bucket
Configuring replication from an unencrypted S3 bucket to an encrypted S3 bucket involves a series of essential steps to ensure the secure and seamless replication of data while maintaining data integrity and confidentiality. This process is crucial for organizations that prioritize data security and compliance with encryption best practices. By leveraging Terraform, users can define the replication configuration, encryption settings, and access controls in a structured and automated manner.
Source and Destination Bucket Configuration
The first step in configuring replication from an unencrypted bucket to an encrypted bucket is to define the source and destination S3 buckets in the Terraform configuration files. The source bucket, which contains the data to be replicated, should be specified along with the destination bucket, where the replicated data will be stored. Additionally, users need to ensure that the encryption settings for the destination bucket align with the desired encryption requirements, such as server-side encryption with AWS Key Management Service (SSE-KMS) or customer-provided keys.
Replication Rules and Encryption Settings
Once the source and destination buckets are defined, users can establish replication rules that govern the objects to be replicated and the replication behavior. It is imperative to configure the replication rules to include encryption settings that align with the encryption requirements of the destination bucket. This may involve specifying the encryption method, key ARN, and any additional encryption settings mandated by organizational policies or compliance standards.
Read more: How To Restart Animal Crossing
IAM Role and Permissions
To enable the secure replication of data from the unencrypted source bucket to the encrypted destination bucket, users must define the necessary IAM roles and policies in the Terraform configuration. These IAM roles should encompass the permissions required for accessing the source bucket, initiating replication tasks, and managing the encrypted destination bucket. By carefully crafting IAM policies, users can enforce the principle of least privilege and ensure that only authorized entities have the requisite permissions for the replication process.
Terraform Apply and Validation
Upon defining the replication configuration, encryption settings, and access controls, users can execute the ‘terraform apply’ command to apply the Terraform configuration and provision the replication setup. It is essential to validate the replication process by monitoring the replication metrics, verifying the encryption status of the destination bucket, and conducting thorough testing to confirm the successful replication of data from the unencrypted source bucket to the encrypted destination bucket.
By meticulously configuring replication from an unencrypted S3 bucket to an encrypted S3 bucket using Terraform, organizations can fortify their data management practices with robust encryption measures, compliance with security standards, and automated replication workflows. This approach not only enhances data security but also streamlines the replication setup while adhering to encryption best practices within the AWS ecosystem.
Testing and Monitoring the Replication Process
After configuring S3 Cross Region Replication using Terraform, it is imperative to conduct thorough testing and establish robust monitoring mechanisms to ensure the effectiveness and reliability of the replication process. Testing and monitoring play a pivotal role in validating the replication setup, identifying potential issues, and proactively addressing any discrepancies to maintain data integrity and compliance.
Testing Replication Behavior
To validate the replication process, it is essential to perform comprehensive testing to confirm that the configured replication rules, encryption settings, and IAM permissions are functioning as intended. This can involve initiating the replication of test objects from the source bucket and meticulously verifying their successful arrival and encryption in the destination bucket. By simulating various scenarios, such as object deletions, updates, and additions in the source bucket, users can assess the responsiveness and accuracy of the replication process.
Data Consistency and Integrity Checks
During testing, it is crucial to conduct data consistency and integrity checks to ensure that the replicated data in the destination bucket aligns with the original data in the source bucket. This can be achieved by comparing checksums, metadata, and encryption attributes of the objects in both the source and destination buckets. Any disparities or inconsistencies discovered during these checks should be promptly investigated and remediated to maintain the fidelity of the replicated data.
Performance and Latency Evaluation
Testing the replication process also involves evaluating the performance and latency of data replication across regions. By measuring the time taken for objects to be replicated from the source to the destination bucket, users can assess the efficiency of the replication workflow and identify any latency issues that may impact the timeliness of data synchronization. This assessment is crucial for optimizing the replication configuration and ensuring timely data availability in the destination region.
Monitoring and Alerting
Establishing robust monitoring and alerting mechanisms is essential for proactively identifying and addressing any anomalies or disruptions in the replication process. By leveraging AWS CloudWatch metrics, users can monitor replication metrics such as replication lag, replication time, and replication errors. Additionally, setting up CloudWatch alarms and notifications enables timely detection of replication failures or deviations from expected behavior, allowing for prompt intervention and resolution.
Compliance and Audit Logging
To uphold compliance with regulatory requirements and internal policies, it is imperative to implement audit logging and monitoring of replication activities. By capturing and analyzing replication logs, users can maintain a comprehensive record of replication events, access attempts, and encryption activities. This audit trail not only facilitates compliance audits but also serves as a valuable resource for forensic analysis and incident response in the event of security or data integrity incidents.
In summary, testing and monitoring the S3 Cross Region Replication process is essential for validating the replication setup, ensuring data consistency and integrity, optimizing performance, and maintaining compliance with security and regulatory standards. By integrating rigorous testing and proactive monitoring into the replication workflow, organizations can bolster their data resilience, mitigate risks, and uphold the integrity of replicated data across AWS regions.
Read more: Delicious Foods Starting With ‘R’ Or ‘S’
Conclusion
In conclusion, the implementation of S3 Cross Region Replication using Terraform presents a compelling opportunity for organizations to fortify their data management strategies with enhanced resilience, disaster recovery preparedness, and compliance with data sovereignty requirements. By leveraging the capabilities of S3 Cross Region Replication, coupled with the automation and infrastructure as code principles of Terraform, businesses can architect robust data replication workflows that span across geographically distributed AWS regions.
The significance of S3 Cross Region Replication lies in its ability to provide a seamless and automated mechanism for replicating data across regions, thereby ensuring data redundancy, disaster recovery preparedness, and compliance with regulatory mandates. With Terraform, the process of defining and provisioning the necessary AWS resources, replication rules, encryption settings, and access controls becomes streamlined and repeatable, fostering consistency and reliability in the replication setup.
Furthermore, the configuration of replication from an unencrypted S3 bucket to an encrypted S3 bucket using Terraform empowers organizations to enforce stringent encryption measures, safeguard sensitive data, and adhere to encryption best practices. This approach not only enhances data security but also aligns with industry standards and regulatory frameworks, bolstering the overall integrity and confidentiality of replicated data.
Testing and monitoring the replication process are pivotal steps in validating the effectiveness, reliability, and compliance of the replication setup. Through comprehensive testing, data consistency checks, performance evaluations, and proactive monitoring, organizations can proactively identify and address any anomalies or discrepancies, ensuring the fidelity and timeliness of replicated data while upholding compliance with security and regulatory standards.
In essence, the combination of S3 Cross Region Replication and Terraform empowers organizations to architect resilient, secure, and compliant data management solutions within the AWS ecosystem. By embracing these technologies and best practices, businesses can strengthen their disaster recovery strategies, enhance data resilience, and uphold the integrity and confidentiality of replicated data across AWS regions, thereby fostering a robust and resilient data management framework in the cloud.
Overall, the integration of S3 Cross Region Replication with Terraform represents a pivotal step towards achieving data resilience, disaster recovery preparedness, and compliance with regulatory mandates within the dynamic and evolving landscape of cloud computing and data management.